- Introduction
- Setup
- Basic Viya VA
- Dot Map
- Scatterplots
- Line Graph
- Widgets
- Analytics
Introduction
This module will introduce you
to SAS
Visual Analytics (VA), a SAS module designed to analyze and
visualize large datasets. We will work through a simple example of
loading data, and visualizing it in different ways as a dashboard.
Setup
In order to work with Viya VA, you will need access to an online Viya
account, since VA runs as a web application. To do this, you must
first login to the VPN using Cisco AnyConnect Secure Mobile
Client. Once you have connected to the VPN, open a web browser and
navigate to
https://sasviya.iaa.ncsu.edu. You will be started in the last
module you were running when you most recently logged out of Viya. To
start SAS Visual Analytics (VA), click the three bars (the hamburger)
left of the SAS Drive text at the top of the screen, and
choose Explore and Visualize Data from the pop-down menu.
Basic Viya VA
In order to visualize, we need to start with a dataset. We'll be using
a modified version of a CSV
activity dataset originally provided
by Peter Aldhous as part of
his Tableau
demo. Much of the material we use here is taken from this demo,
then updated for Viya VA and extended to apply some of the
visualization principles we learned during the summer visualization
lectures.
Once you've downloaded the activity dataset to your computer, open it
in Excel and spend a few minutes familiarizing yourself with its
different fields.
Loading Data
To start, we need to load the activity dataset into Viya VA.
- Launch Viya VA.
- Click the "Start with Data" button near the top of the screen.
- Click the "Import" option at the top of the list of available
datasets. Click ">> Local Files" from the "Add data sources..."
options, then choose "Microsoft Excel" from the drop-down menu. Locate
the
USDA_acctivity_dataset.xlsx that you downloaded,
select it, and click "Open."
- The "Add to Import" dialog will appear. Keep the default settings
and click the "Add" button.
- Information about the dataset will be displayed, with a variety of
options to control the import process. Keep the default selections and
click the "Import item" button in the upper-right corner of the
screen.
- A small green line near the top of the screen will inform you "The
table was successfully imported." Click the "OK" button to complete
the import operation.
Now, you will be taken back to the VA screen, with the data from
the imported dataset displayed in the Data panel on the left-hand side
of the screen
Categories and Measures
Once you load the USDA Activity Dataset into Viya VA, it should
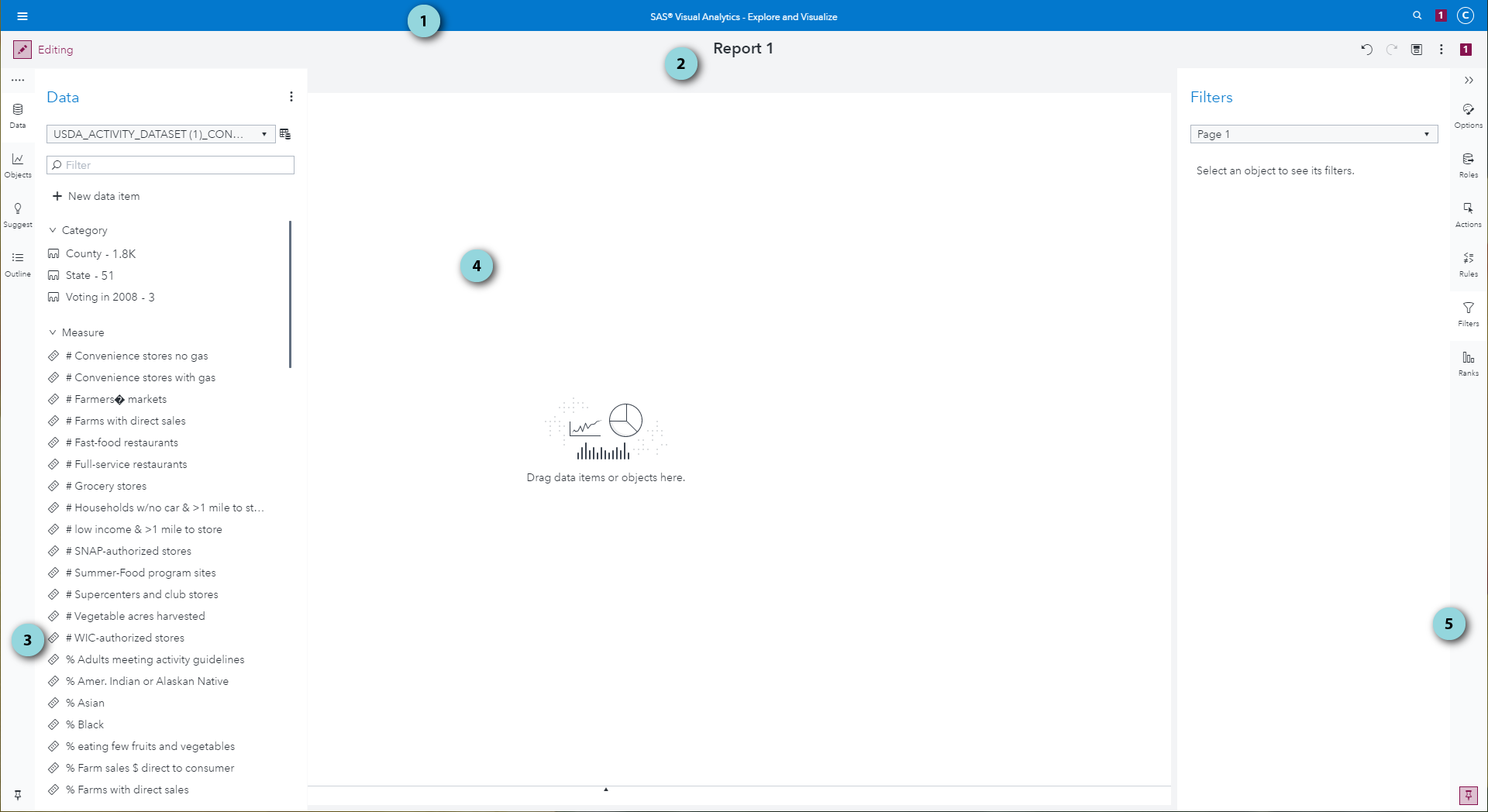
present a window that looks similar to this.
Viya VA's initial page after importing the USDA dataset.
|
Based on the above example, the following regions of the VA
workspace correspond to different presentation management.
- Application bar. Used to access other SAS Viya
applications.
- Tab bar. Used to create new tabs and manipulate existing
tabs via the trip-dot menu on the right of each tab.
- Left pane. Used to work with data, report objects, and the
report outline.
- Canvas. Used to visualize data as a dashboard.
- Right pane. Used to control details about the report and
individual report objects.
Notice that Viya VA has divided the data in the Excel file
into Category, Measure, and Aggregated
Measure. Categories and Measures correspond to Dimensions and
Measures in Tableau: categorical or qualitative data fields are
considered categories, and numeric or quantitative information are
considered measures. Aggregated Measures allow you to apply an
aggregation (e.g., average, median, etc.) to a measure and save it as
a new data field. This can also be done to the measure directly, but a
direct aggregation then applies to all visualizations that use the
measure. There is no way to independently vary the aggregation for a
measure used in a visualization, similar to the way aggregations can
be chosen for data on the rows in Tableau.
As with Tableau, you can convert from one data role to another:
hover of the field name, click the double down-arrows that appear to
the right of the name, then choose an available option from the
Classification drop-down menu. As an example, we will
convert State and County from generic Category to
specific Geographic roles. Hover over the State name, click the
down-arrows, and in the "Classification" drop-down menu, choose
"Geography". In the "Edit Geography Item" dialog, select "US State
Names" in the "Name or code context" drop-down menu. Click OK,
and State is now defined as a geographic field representing US
state names. State will now appear in a new "Geography" section
in the list of data items. Follow a similar set of steps
for County, but choose "County or Region Names" rather than "US
State Names" for "Name or code context" menu.
A map showing average % smokers by state
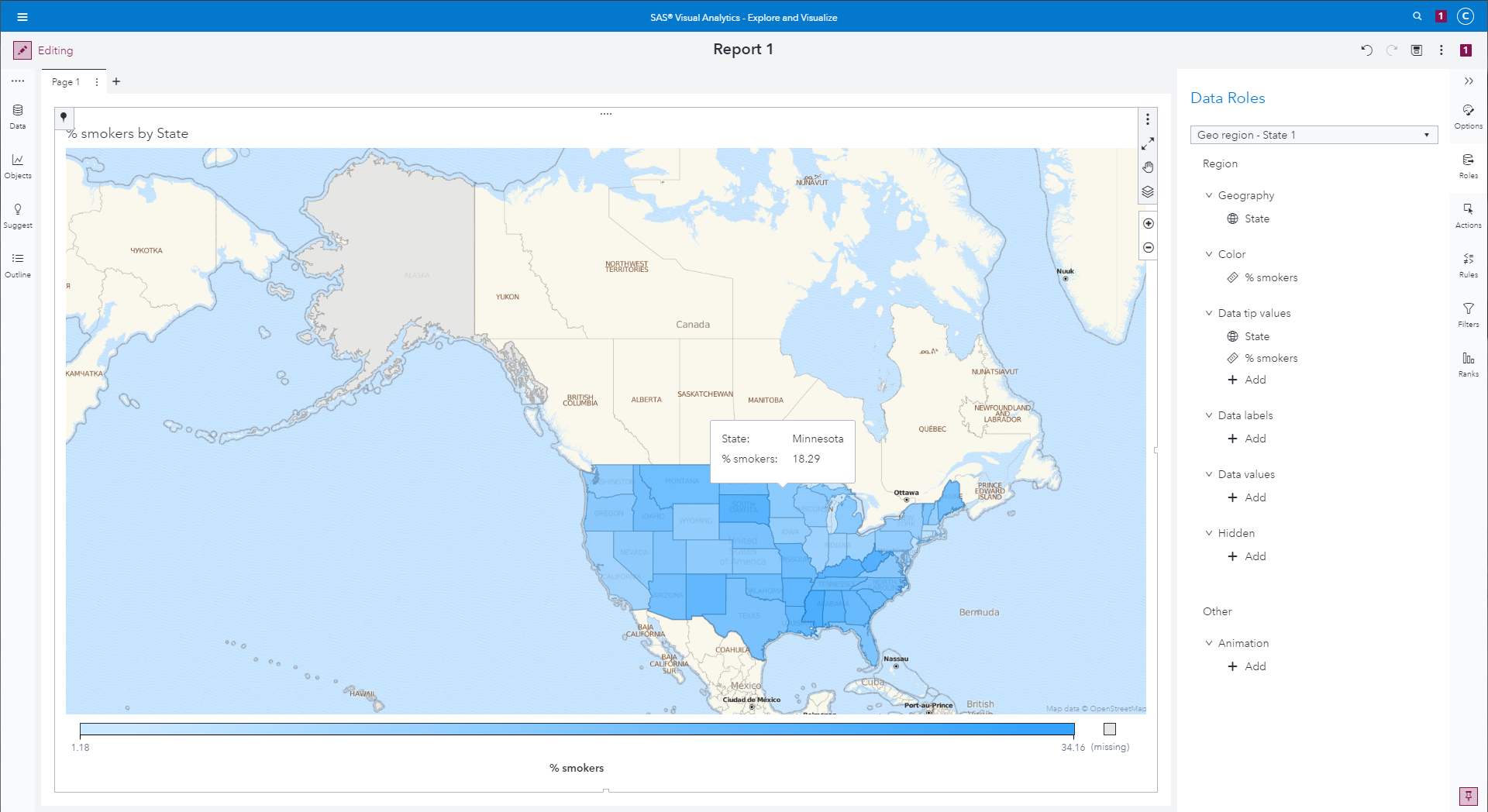
|
The most common reason to distinguish between dimensions and measures
is because of how they act in a visualization. In general, selecting a
category creates an axis of individual categories headings. Selecting
a measure creates an axis showing a continuous scale over the
measure's range of values. You can try this:
- Click on the "Objects" icon in the
menu on the left pane, and drag the "Bar Chart" item into the data
canvas to create a placeholder bar chart.
- Click on the "Roles" icon in the menu
on the right pane, and choose "State" for Category and "% smokers" for
measure.
- Right-click on the "State" label for
the vertical axis and choose "Sort → State: Ascending" to sort by
state name rather than median % smokers.
- Click on the "Options" icon in the
menu on the right pane, and in the "Bar" drop-down section, choose the
"Direction: Up" button (the button on the right).
- Further down in the "Bar" section,
click the "Data labels" checkbox.
- In the "X Axis Options" section,
click the "Rotate value label" checkbox.
A vertical bar graph showing average % smokers by state
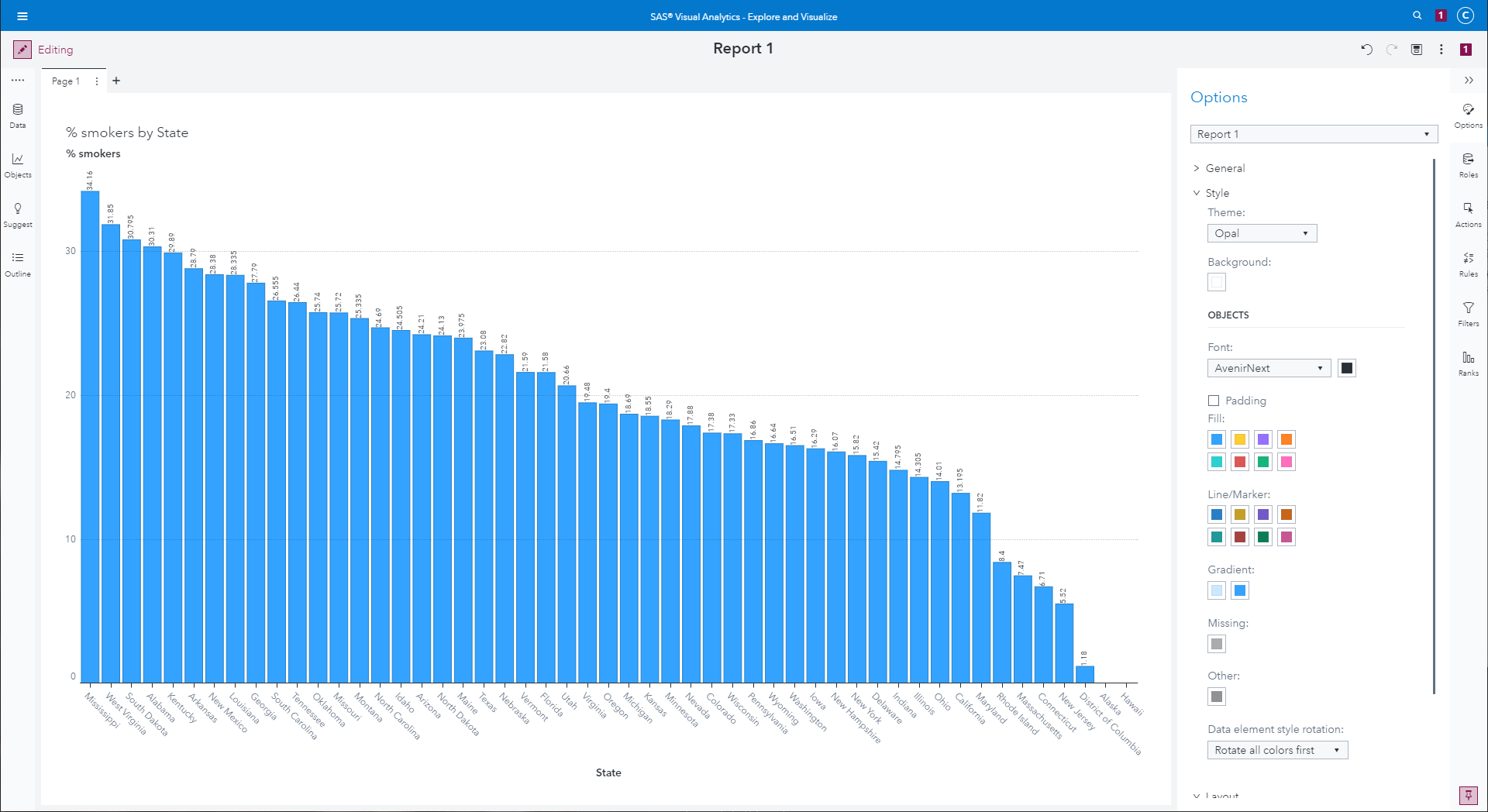
|
Now, you should see a horizontal bar chart showing the median of "%
Smokers" for each of the individual states. To switch to average
percentage of smokers, click the "Data" icon, hover over the "%
smokers" measure, click the down arrows, and under the
"Aggregation:" label click the drop down menu and choose "Average."
The graph will update to show average % smokers per state.
Field Type
Each field also has a small icon to its left. This identifies its
current data type: an "M"-like icon for category, a globe for
geography, and a ruler rotated 45° for measure and aggregated
measure. Calculated fields add a small calculator icon superimposed on
top of the data type.
Dot Map
To start our example visualization, we will generate a dot map of the
adult obesity rate for each state.
- If the canvas has visualization(s) in
it, clear them by clicking on the visualization, then pressing "Del"
to clear the canvas.
- Ensure "State" is a geography data
type by clicking the Data icon in the left pane, hovering over the
"State" Category and clicking the down arrows, changing the
Classification to "Geography," then choosing "US State Names" in the
"Name or code context:" field.
- Click the "Objects" icon in the left pane, and drag "Geo
Coordinate" onto the canvas.
- Click on the "Roles" icon in the
right pane and map the following data fields: Category → State
– 51; Size → Adult obesity rate (do this by clicking on the
Size label and choosing Adult obesity rate to replace anything it is
currently assigned to.)
- You should see a map with one blue dot in the center of each state
throughout the United States.
- By default, VA generate a Bubble map. If this did not happen,
click on the "Options" icon in the right pane, open the "Coordinate"
section, and choose the "Bubbles" button in the "Data layer render
type:" option.
- By default, VA aggregates multiple data points for a given region
(in our case, for a given state) by summing. We want to average the
adult obesity rate, so click on the "Data" icon in the left pane,
hover over Adult obesity rate, click the down arrows, and under the
"Aggregation:" drop down menu, choose "Average."
- We also want to colour the bubbles in a double-ended fashion based
on Adult obesity rate. Click on the "Rules" icon in the right pane,
then click "New rule." Choose "Adult obesity rate" from the list that
appears, choose the operator "<" from the drop-down menu, enter a
value of 28.5 (the median Adult obesity rate). Then, click on the
"Style:" button and choose a shade of blue.
- Create a second rule and perform the identical steps, except using
an operator of ">=" and a style value that's a shade of red.
- The final map shows blue and red circles sized based on the
average adult obesity rate, and colored based on whether the state's
average obesity is below (blue) or above (red) the overall median.
- To rename the report page, double-click on the "Page 1" tab title,
and change it to "Map."
A map showing average obesity rate by county using a red–blue
colour scale: red for values above the median, blue for values below
the median, and saturation for values farther from the median.
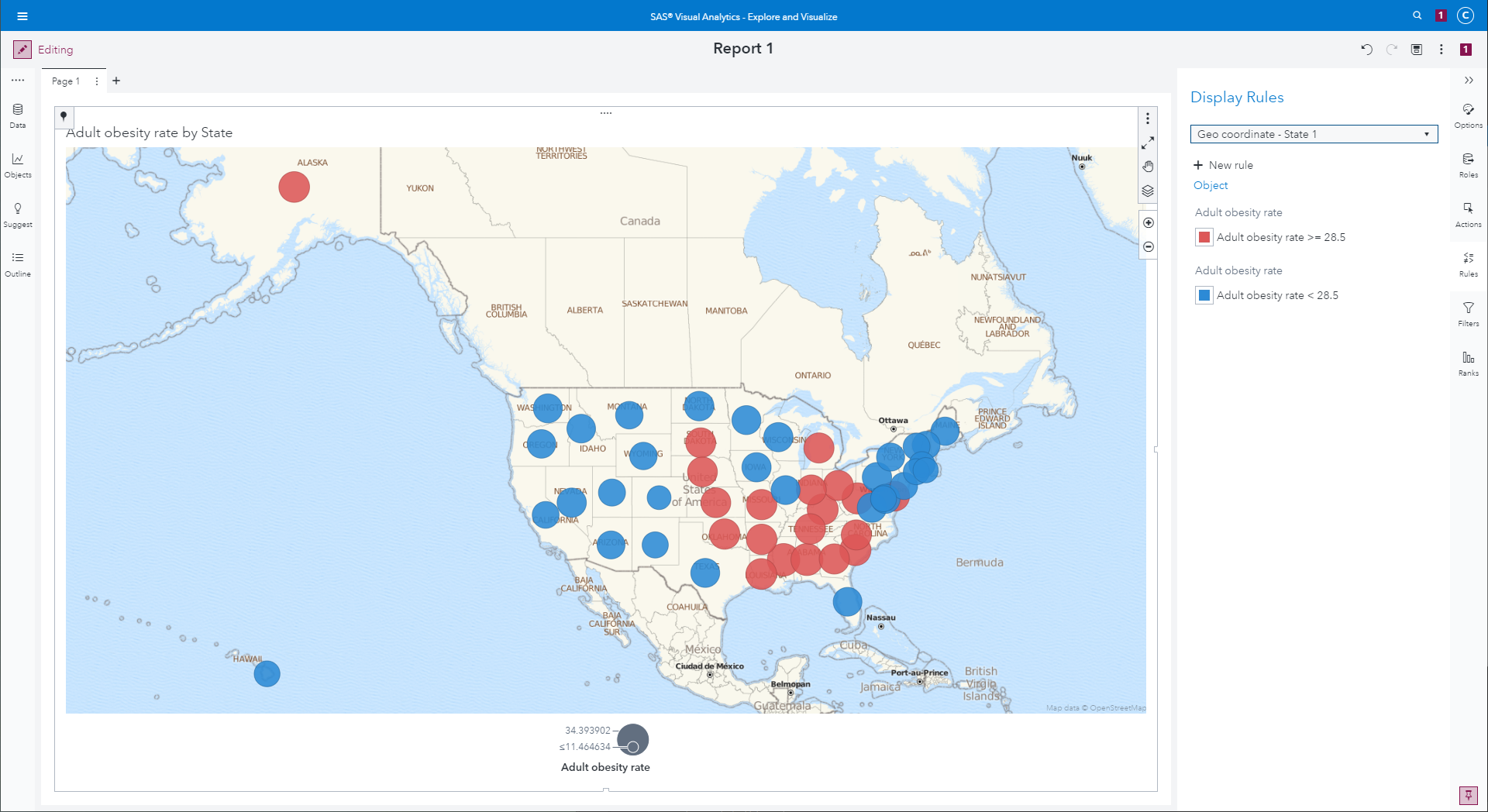
|
Scatterplots
Next, we'll create some scatterplots to compare adult obesity rate
to other, possibly related measures.
- Click the "+" in the Tab bar to create a new report page.
- Double-click the tab's default title and change it to
"Scatterplot."
- Click on the "Objects" icon in the
left pane, select "Scatter Plot" and drag it to the canvas, re-open
the "Objects" list, select "Scatter Plot" again and drag it to the
canvas, positioning it to the right of the first scatterplot. Do this
one more time to add a third scatterplot.
- Click on the leftmost scatterplot,
click on the "Roles" icon in the right pane, and add "% smokers" and
"Adult obesity rate" to the "Measures" list.
- Click on the middle scatterplot,
click on the "Roles" icon in the right pane, and add "% eating few
fruits and vegetables" and "Adult obesity rate" to the "Measures"
list.
- Click on the middle scatterplot,
click on the "Roles" icon in the right pane, choose % eating few
fruits and vegetables and Adult obesity rate from the Data Items list,
and click OK.
- Click on the rightmost scatterplot,
click on the "Roles" icon in the right pane, choose % who do not
exercise and Adult obesity rate from the Data Items list, and click
OK.
- Using the Data panel, change the
aggregation method from Sum to Average for % smokers, % eating few
fruits and vegetables, and % who do not exercise.
- For each scatterplot, select it, click the "Options" icon in the
right pane, in the "Style" section click the upper-left colour square
in the "Line/Marker:" section and choose a colour for the marks (green
for the left scatterplot, purple for the middle scatterplot, and red
for the right scatterplot). In the "Scatter Markers" section choose a
"Transparency:" of 40%, in the "Fit Line" section choose a "Type:" of
"Cubic", in the "X Axis Options" select "Fixed maximum:" and set the
value to 100, and in the "Y Axis Options" select "Fixed maximum:" and
set the value to 45.
Three scatterplots showing comparing average obesity rate by county
to percentage of smokers, percentage eating few fruits and
vegetables, and percentage who do not exercise.
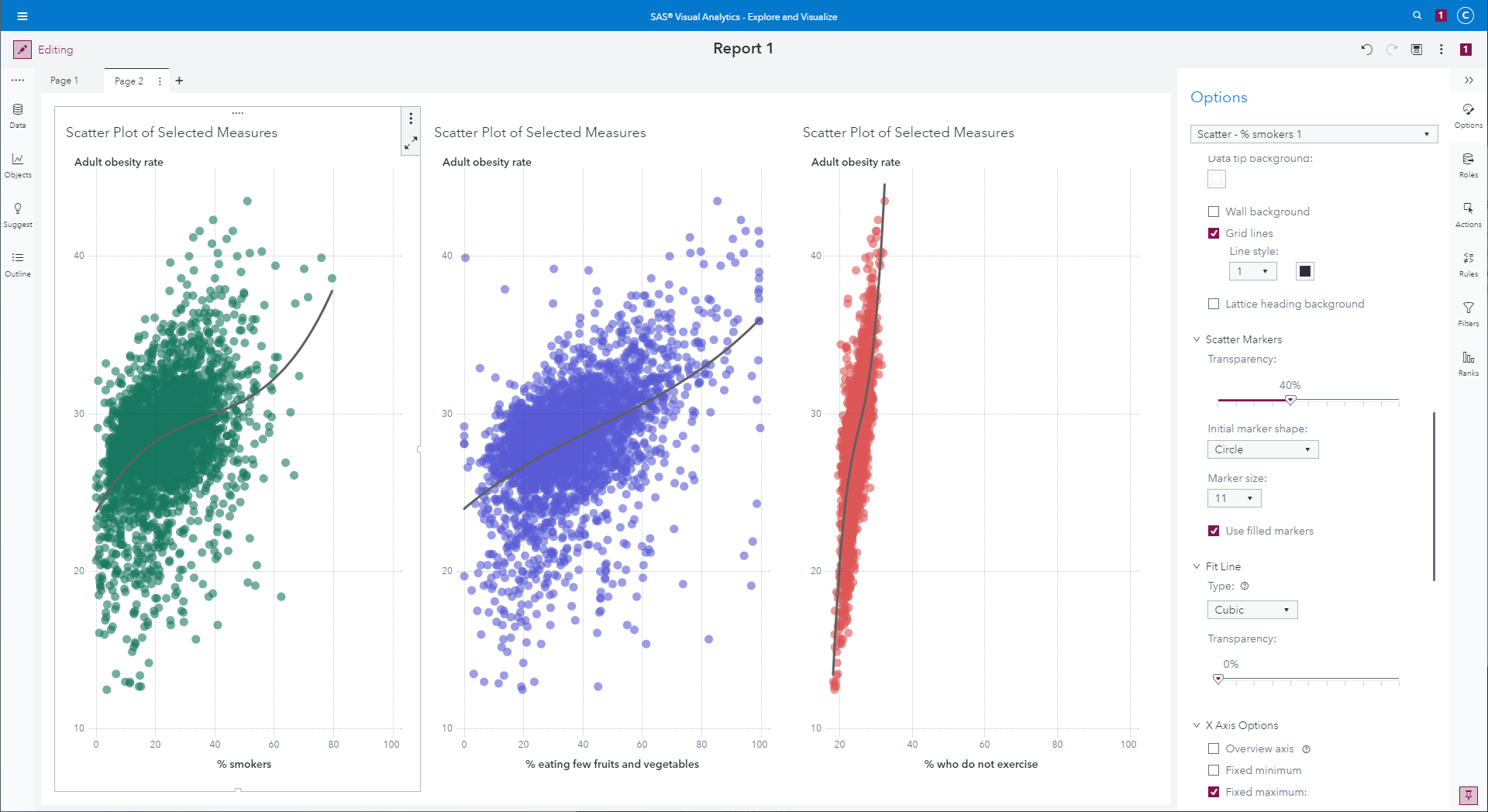
|
There appears to be a strong correlation between adult obesity and
all three potential predictor variables, although "% who do not
exercise" seems to have the strongest impact on obesity rate
(i.e., the steepest slope.)
Dual-Axis Line Graph
Often we want to compare variables across a sequence over time or a
categorical dimension like county or state. Here, we'll build a line
graph to represent Adult Obesity and % Smokers, to see if there's any
additional visual correlation between the two.
- Click the "+" in the Tab bar to create a new report page.
- Double-click the tab's default title and change it to "Dual-Axis
Graph."
- Click on the "Objects" icon in the
left pane, select "Dual Axis Line Chart" and drag it to the canvas.
- Click on the "Roles" icon in the
right pane and map the following data fields: Category → State -
51; Measure (line) → Adult obesity rate; Measure (line 2) →
% smokers.
- Right-click the "State" label for the
horizontal axis and choose "Sort > State: Ascending."
- Click on the "Options" icon in the
right pane and change the following options:
- For the first "Line/Marker:" button, change the colour to orange.
- For the second "Line/Marker:" button, change the colour to blue.
- In the "X Axis Options", select "Rotate value label."
- In both the "Y Axis Options" and "Y2
Axis Options", select "Fixed minimum:" and "Fixed maximum:" and set
values for both axes to 0 and 40, respectively; this ensures the lines
span a common range of percentages.
Dual-axis line graphs comparing sum of obesity rate by state to
sum of percentage of smoker.
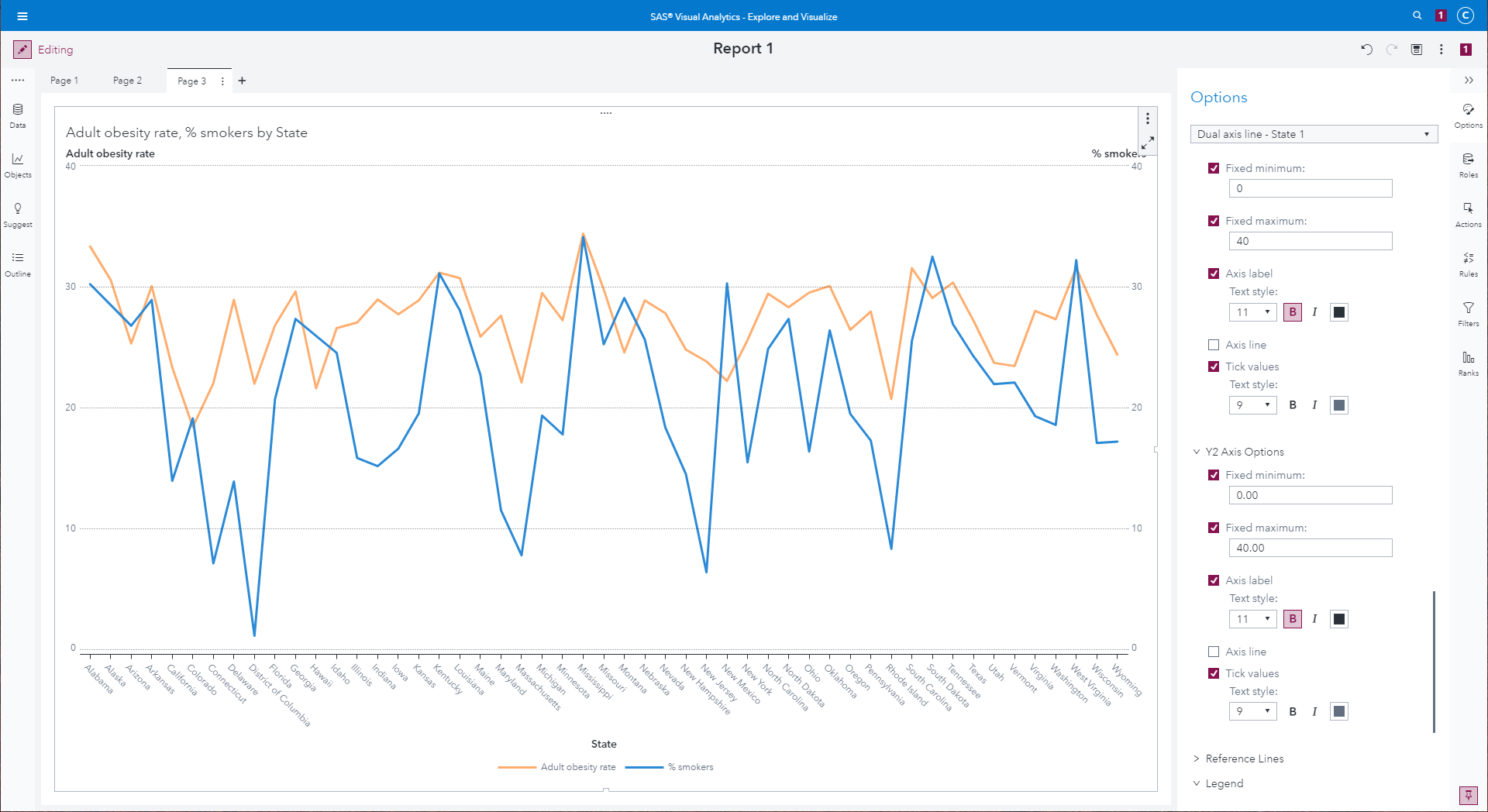
|
At this point, we have a basic dual-axis graph, but there are a few of
formatting modifications we can make to improve on VA's defaults.
- Since we're aggregating across all counties in a state, we want
the average obesity and smoker rates, not the sum of all counties, so
ensure both Adult obesity rate and % smokers are aggregating as
Average.
- We'd like the left and right axes to show values with a "%" sign
at the end. To do this, click the "Data" icon, hover over the Adult
obesity rate measure, click the down arrows, click the pencil icon
under "Format:" and change choose "Percent."
- Do the same operation for the "% smokers" measure.
Dual-axis line graphs comparing sum of obesity rate by state to sum
of percentage of smoker, but with incorrect percentages on the
vertical axes.
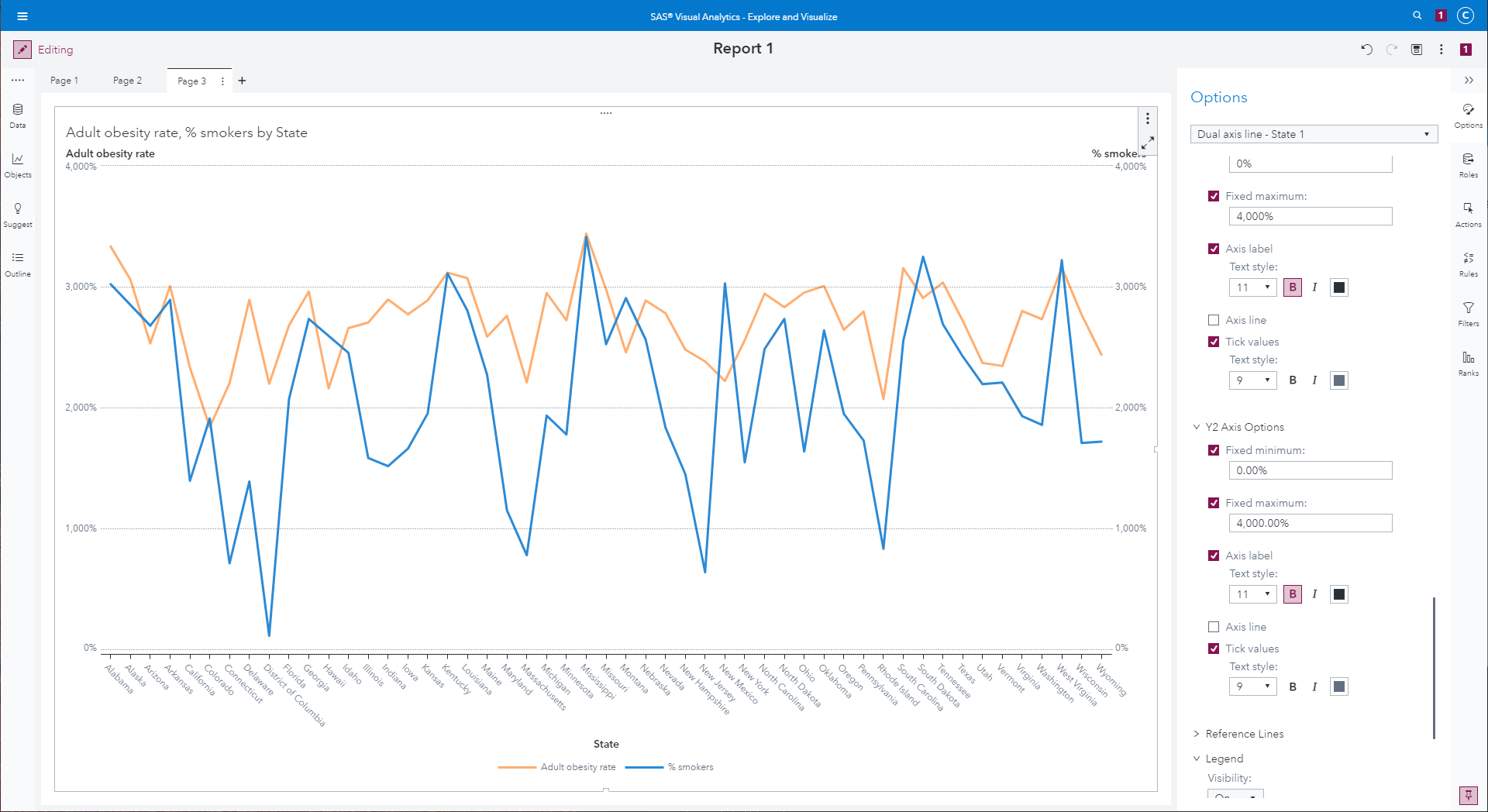
|
Although this adds a "%" to the values on the vertical axis, it also
exposes a problem: percentages run from 0% to 4,000%, because the
"Adult obesity rate" and "% Smokers" columns are coded on a range
0–100, and not 0.0–1.0. You can confirm this by selecting
"Manage Data" from the menu to the left of "SAS Visual Analytics" in
the titlebar, choosing "USDA_ACTIVITY_DATASET" from the list of
available datasets, then selecting the "Sample Data" tab. % smokers is
the seventh column, and shows values like 20.87, 21.74, and
32.72. Switch back to "Explore and Visualize Data" once you're done.
To address this, we will create a new calculated field that
spans the 0.0–1.0 range we want.
- Choose the "Data" icon.
- Select "Calculated item" from the "New data item" menu.
- Choose a "Name:" of "% Adult Obesity 0.0-1.0"
- Click the "Operators" tab, reveal the "Numeric (simple)" options,
and drag "# x / y" to the "number" box in the canvas.
- Right-click the first "Number" button, choose "Replace with" and
select Adult obesity rate from the pop-up menu.
- Click inside the second "number" field and enter 100.0.
- Click "OK" to save the calculated item.
Notice now that there is a "% Adult Obesity 0.0-1.0" measure in the
Data list, and the measure's data type ruler is covered by a
calculator, indicating it is a calculated field. Execute the same set
of operations to create a calculated field on the range 0–1 for
"% smokers."
To fix the dual line graph, click the "Roles" icon, and replace the
existing measures with "% Adult Obesity 0.0-1.0" and "% smokers
0.0-1.0" for "Measure (line)" and "Measure (line 2)", respectively.
Unfortunately, VA resets back to its default values, so you must
also re-do the following changes.
- Right-click on "State" and choose "Sort > State: Ascending"
- Open the "Data" panel, right-click on "% Adult Obesity 0.0-1.0"
and choose "Format: → Percent" and "Aggregation: → Average";
apply the same formatting to "% smokers 0.0-1.0"
- Open the "Options" panel, and change the "Fixed maximum:" for both
the "Y Axis Options" and "Y2 Axis Options" to 40%, since VA has
changed them to 4000%.
Once this is done, we have the same dual line graph, but with
percentages correctly shown on the right vertical axis.
Dual-axis line graphs comparing sum of obesity rate by state to sum
of percentage of smoker with correct percentages on the vertical
axis.
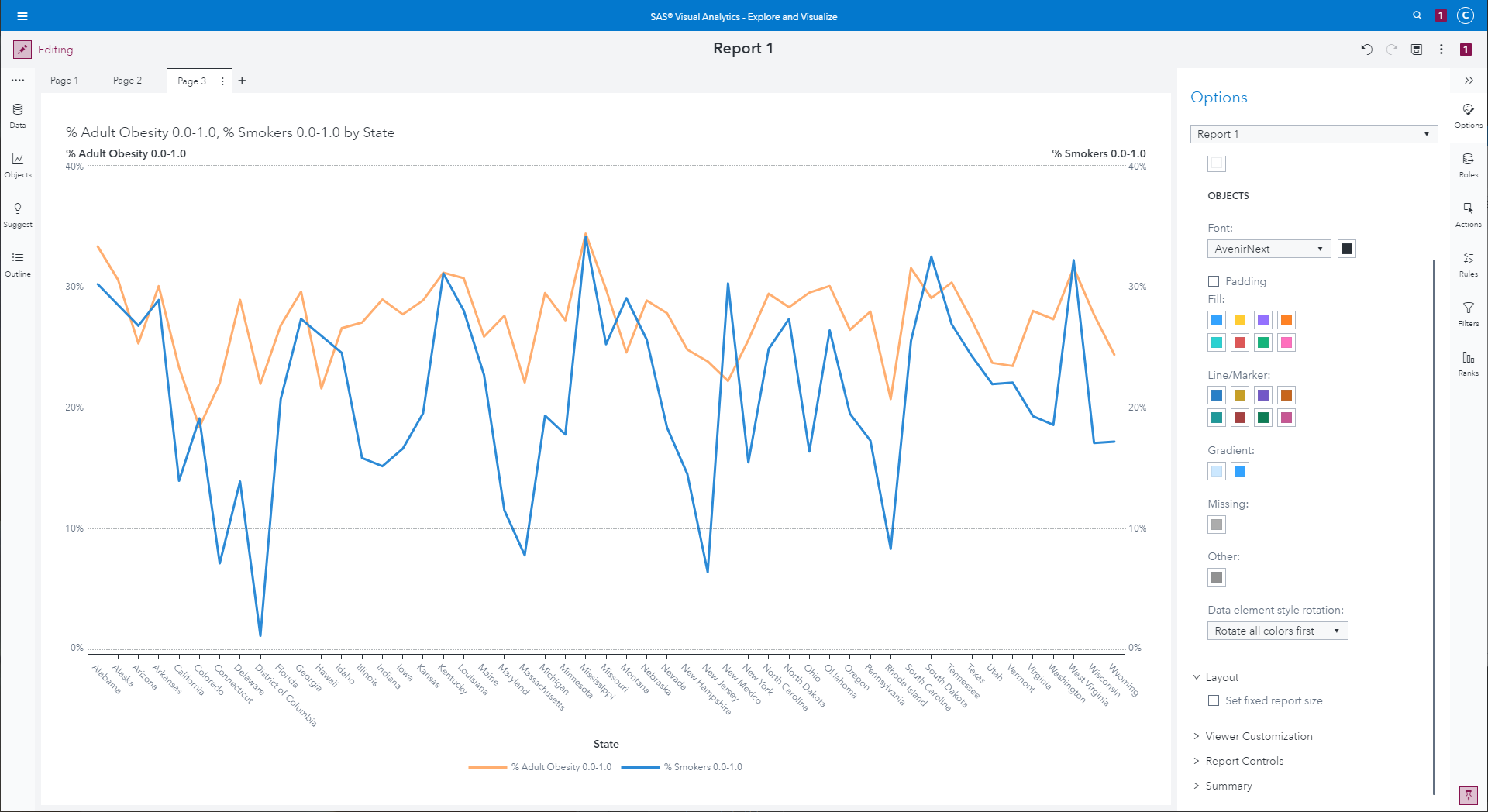
|
VA provides a number of interactive widgets to allow you to control
what is displayed within your visualizations. These act in a manner
similar to Action Filters in Tableau: selections within the widgets
automatically apply filters to one or more visualizations. Unlike
Tableau, however, the widgets can simply be dropped and configured on
a report, as opposed to building a separate "visualization" and
linking it as an action filter in a Tableau dashboard. The interactive
widgets included in VA include:
- Button Bar. A list of buttons,
whose number and labels are defined by a category field.
- Drop-Down List. A drop-down
menu, whose length and entries are defined by a category field.
- List. A checkbox list whose
length and entries are defined by a category field.
- Slider. A double-ended slider
whose minimum and maximum values are defined by a measure field.
- Text Input. A text field where
you can enter the name of a category field to filter the visualization
to show only entries tied to the named field.
Viya VA also provides a number of containers, to control how your
content is positioned and organized. These include:
- Precision Container. Allows you to place, align, and size
objects explicitly within a container. Objects can overlap.
- Prompt Container.Used to group prompt controls within a
report. Only prompt controls can be placed inside a prompt container.
- Scrolling Container.Displays content in a scrolling
layout. Each object fills the entire container, you must scroll to
see other objects.
- Stacking Container.Display objects as thought they are
a slide deck. Only one object is displayed at a time. A control bar
allows you to move between objects (slides).
- Standard Container.Positions content horizontally or
vertically. When possible, content is resized so multiple objects
can be displayed without scrolling.
The concept of a "dashboard" in Viya VA is different than
Tableau. Rather than having separate worksheets and dashboards, Viya
VA assumes you will place a container on the canvas, build multiple
visualizations directly within the container, then select and position
them as you like based on the container's capabilities. As an example,
let's use a standard container to create a dashboard that has the map
we previously built on the top, and the three scatterplots and
dual-axis line graph below that.
Unfortunately, SAS claims that as of the current version of VA, there
is now way to copy content from one report page to another. You can,
however, move content. You can do this with the following steps."
- Click the "+" in the Tab bar to create a new report page.
- Double-click the tab's default title and change it to "Dashboard."
- Click the Map tab to select the map visualization.
- Right-click inside the map visualization, and choose "Move to >
Dashboard" to move the map visualization to the Dashboard page. It
will disappear from the map page and re-appear on the Dashboard page.
- Perform the same operation four times to move the three
scatterplots and the dual-axis graph to the Dashboard page.
- Select the Dashboard tab, and you should see all five
visualizations. Rearrange them by dragging them and changing their
display properties in the Options panel until you have a dashboard
layout you are happy with.
Map, three scatterplots, and a dual-axis graph.
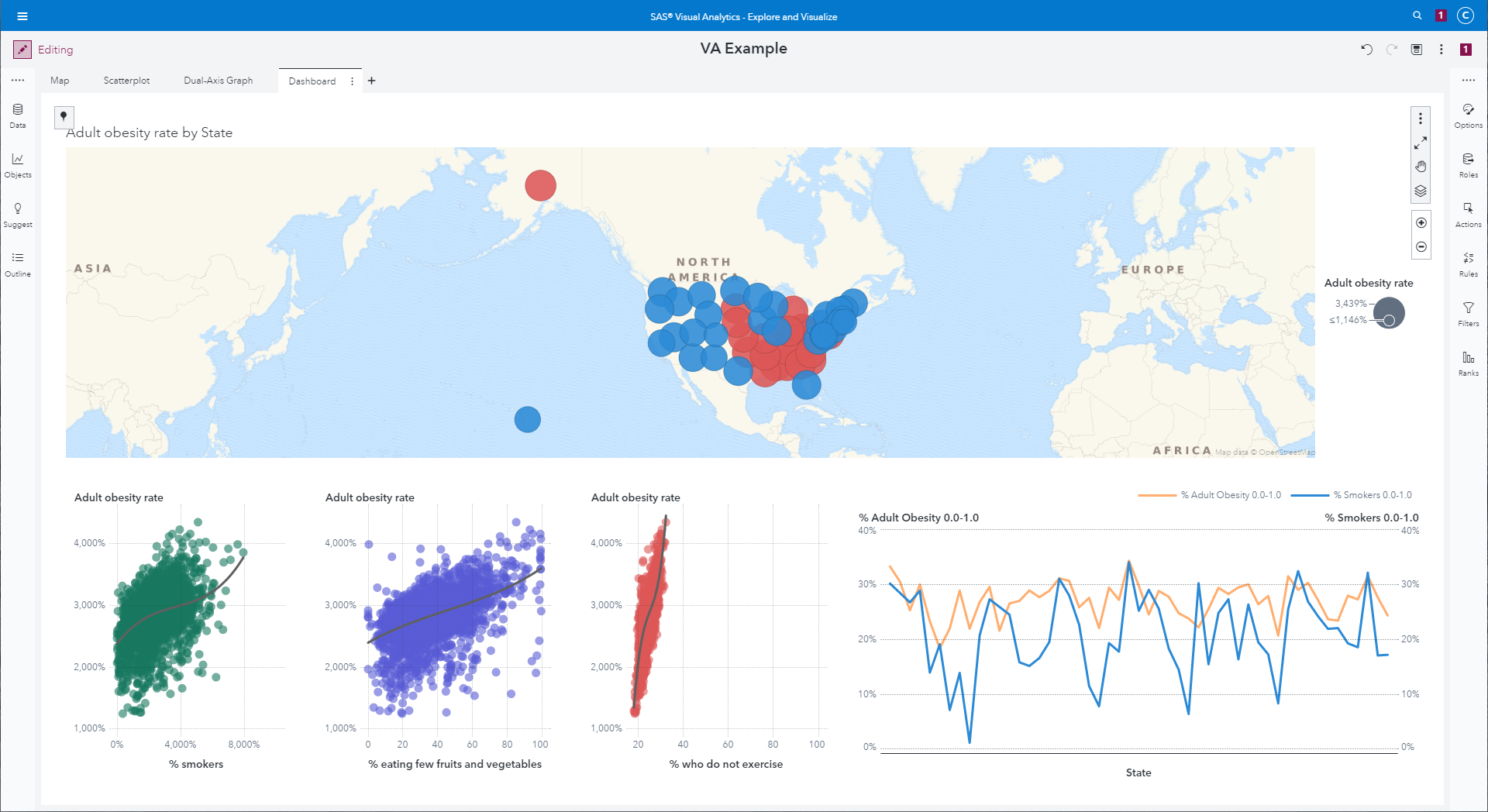
|
Next, we'll create a list of State names, then filter both the
visualizations based on the state(s) selected by the user. To do
this
- Click on the "Objects" icon.
- Choose "List" in the "Controls" section, and drag it to lie right
of the map, scatterplots, and dual-axis graph.
- Click on the "Roles" icon.
- Choose "State" for the "Category" role.
- Click on the "Actions" icon.
- Here, we define actions based on selections in the list. We can
use the selections as a filter for individual visualizations, or all
the visualizations on the canvas. Since we want to filter all the
visualizations, activate the checkbox for "Automatic actions on all
objects," and confirm "One-way filters" in the drop-down menu. Also
select "Display filter breadcrumb" so we can see the active filters on
the visualization.
- You can dynamically resize the width of the list by hovering over
its left border and, clicking and holding the left button when the
pointer changes to a left-right arrow, and dragging left or right.
Map and three scatterplots with a list widget controlling which
state data to visualize.
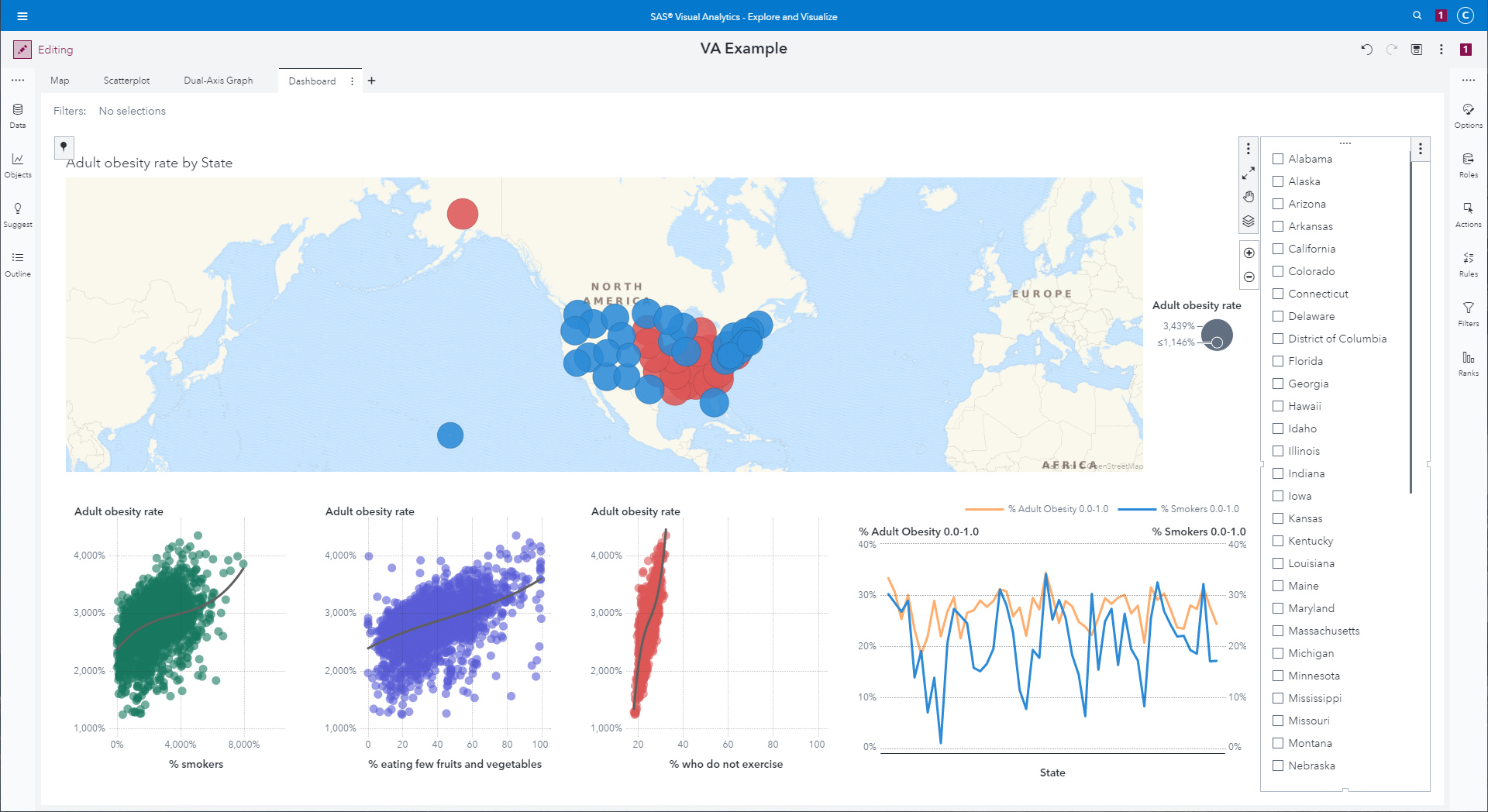
|
Now, when you select a state in the list, that map will zoom to
that state and the scatterplots will reduce to contain only samples
from the selected state. You can select multiple states, or
right-click and choose "Clear selection" to reset the filters.
Suppose we also wanted to add the ability to filter based on
how individuals voted (D, R, or missing value). We will first convert
the map to use choropleth filled regions. Then, we will add a button
bar to filter by "Voting in 2008".
- Click on the geomap to select it.
- Click on the "Rules" icon, select each of the two colour
rules, and click the trash can to delete them.
- Right-click on the map, and choose "Change Geo coordinate to >
Geo region."
- Click the "Objects" icon on the left, Choose "Button bar" in
the "Controls" section, and drag it to lie below the state list
widget.
- Click on the "Roles" icon.
- Choose "Voting in 2008" for the
Category role.
- Click on the "Actions" icon.
- Choose "Automatic action on all objects", a drop-down value of
"Two-way filters", and ensure "Display filter breadcrumbs" is
selected; two-way filters allows both the voter and state filters to
be active at the same time.
- Click on the "Options" icon.
- In the Title: drop-down, choose Custom title and enter a title of
"Select Voter Type."
- In the Button Bar section, under "Direction" click the vertical
direction button (the second button).
Map and three scatterplots with a list widget and a button bar
controlling which state data and party selected in the 2008 election
to visualize (Republicans from Arizona and California).
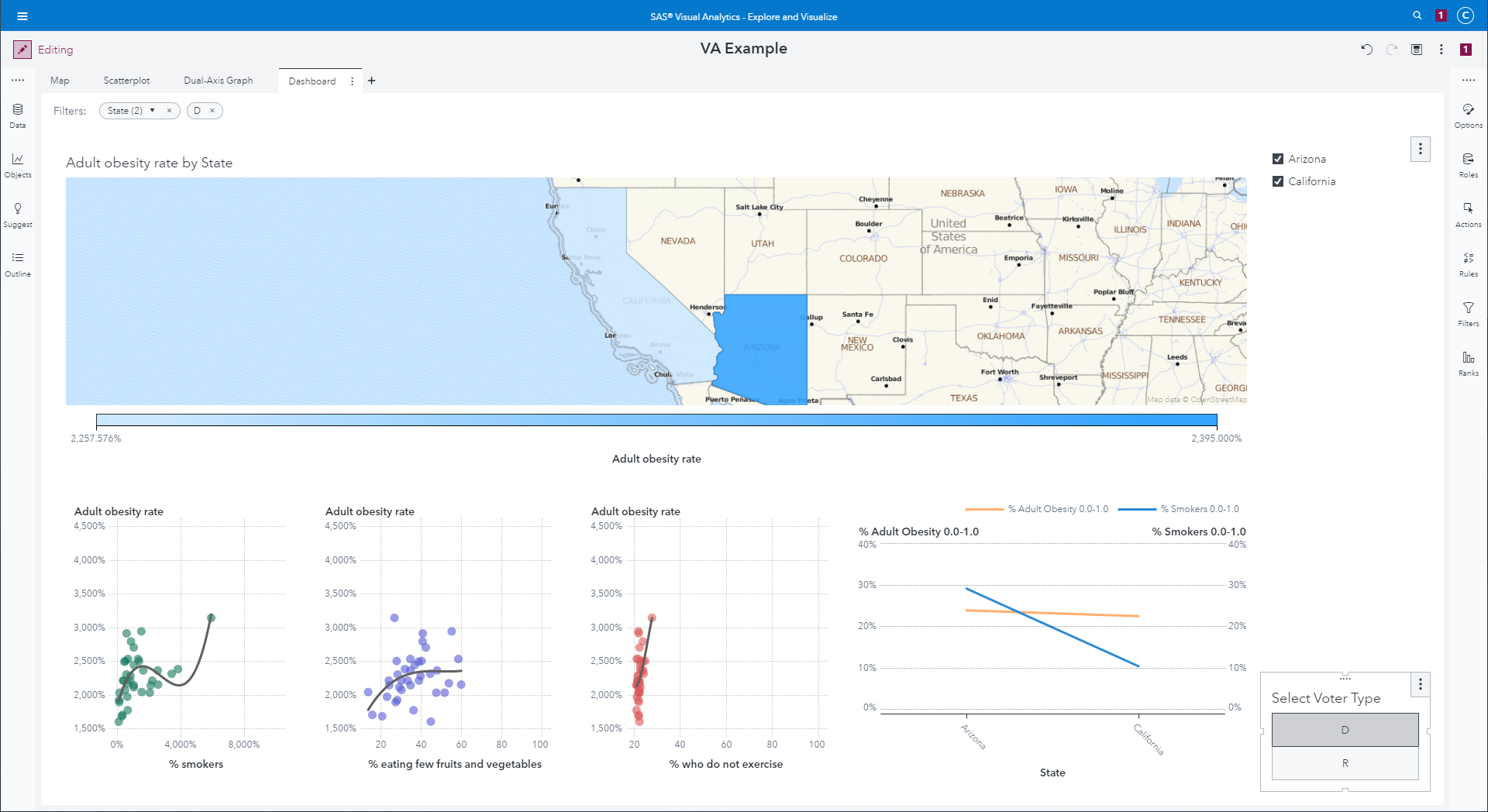
|
Filters are applied in a Boolean AND fashion, so the map above
shows individuals who live in California and Arizona, and who
voted Democrat in the 2008 election.
Analytics
One of Viya VA's major advantages over other visualization tools
like Tableau is its built-in analytics objects. Because VA is
integrated directly into Viya, it has access to all of the statistical
power of Viya. VA provides a number of analytic, visual statistics,
and visual data mining and machine learning objects that can be
applied directly to the data in your visualization report.
As an example, suppose we wanted to use a decision tree to
see how well % eating few fruits and vegetables, % smokers, and %
Low-income receiving SNAP predict Adult obesity rate. To do this
- Click the "+" icon at the top of the report to create a new report
page.
- Click the "Objects" icon.
- In the "SAS Visual Statistics" section, locate "Decision Tree" and
drag it onto the new canvas.
- Click the "Roles" icon.
- Under "Response", click "Add" and choose % Adult Obesity 0.0-1.0.
- Under "Predictors", click "Add" and choose % eating few fruits and
vegetables, % Low-Income receiving SNAP, and % smokers.
Decision tree, variable importance, assessment line graph, and
split frequency for a decision tree predicting Adult obesity
rate from % eating few fruits and vegetables, % Low-income receiving
SNAP, and % smokers
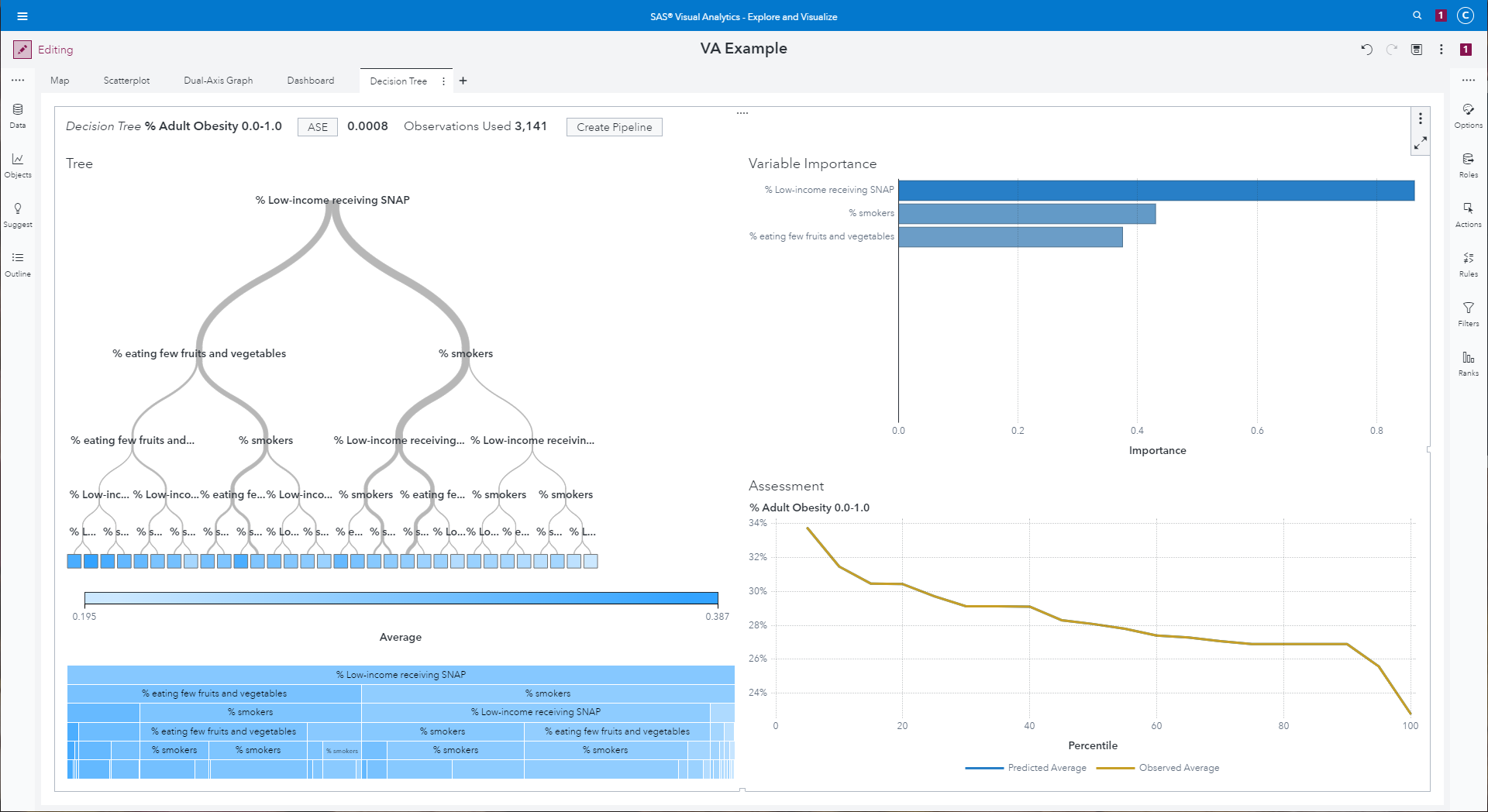
|
VA computes results and displays them as four visualizations,
clockwise from the upper-left: a tree identifying splitting parameters
at each internal level, and rules describing a leaf as well as the
number of samples that fall into the leaf at the bottom of the tree; a
variable importance graph, an assessment line graph showing how predicted
and observed average correlate, and finally a treemap that shows how
much of the sample data flows left and right at each split in the
tree.