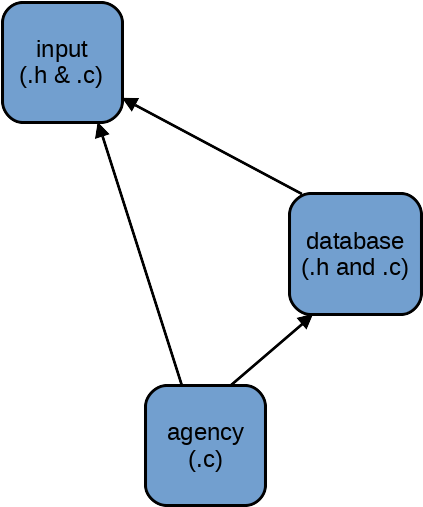
Figure: components and dependency structure
For this project, you will write a program that manages a temp agency that maintains a database of employees. Companies contract with the agency to hire employees on a temporary basis. At start-up, the program will read one or more files containing employees and store them in the agency database. It will then let the user enter commands to view the employees and to assign them to various companies.
The following shows an execution of the program. The text that's in bold shows what the user types. The rest is output from the program. Here, the user asks the program to read employees from two files, list-b.txt and list-c.txt. The "cmd> " at the start of some lines is a prompt for the user.
The user first asks for a list of all the employees. The output lists employees from the input files, one per line. Each employee is listed with an ID number on the left, a first and last name, their skill, and the company to which they are assigned or "Available" if they are not currently assigned to a company. The user then asks for a list of just the employees that have the skill, Sales. Afterwards, the user assigns several employees to the company, MaxRealty, and then lists all employees who are assigned to that company. Next, the usre removes one of the employees assigned to MaxRealty and re-lists the employees assigned to the company to show this person was removed. Finally, the user then quits the program.
$ ./agency list-b.txt list-c.txt cmd> list list ID First Name Last Name Skill Assignment 0165 Phillip Sanders Accounting Available 0337 Timothy Donnelly Accounting Available 1234 Jessica Strong IT Available 1945 Maria Gilligan Administration Available 2334 James Bush Sales Available 2870 Bonnie Jones Sales Available 3567 Don Hernandez IT Available 3987 Nancy Clyburn Administration Available 3988 Jerry Johnson Sales Available 4067 Jack Patel Sales Available 4100 Jill Brothers IT Available 5678 Alice Chang Administration Available 5912 Alex Smothers IT Available 6754 Bob Lucas Sales Available 7145 Margaret Sutton Sales Available 8097 Lisa Dominguez Marketing Available 8564 Mark Thompson Marketing Available 9012 Mike Nguyen Marketing Available 9665 Jenny Chavez Administration Available 9873 Mary Chavez IT Available cmd> list skill Sales list skill Sales ID First Name Last Name Skill Assignment 2334 James Bush Sales Available 2870 Bonnie Jones Sales Available 3988 Jerry Johnson Sales Available 4067 Jack Patel Sales Available 6754 Bob Lucas Sales Available 7145 Margaret Sutton Sales Available cmd> assign 3987 MaxRealty assign 3987 MaxRealty cmd> assign 4067 MaxRealty assign 4067 MaxRealty cmd> assign 2870 MaxRealty assign 2870 MaxRealty cmd> list assignment MaxRealty list assignment MaxRealty ID First Name Last Name Skill Assignment 3987 Nancy Clyburn Administration MaxRealty 2870 Bonnie Jones Sales MaxRealty 4067 Jack Patel Sales MaxRealty cmd> unassign 2870 unassign 2870 cmd> list assignment MaxRealty list assignment MaxRealty ID First Name Last Name Skill Assignment 3987 Nancy Clyburn Administration MaxRealty 4067 Jack Patel Sales MaxRealty cmd> quit quit
As with recent projects, you'll be developing this one using git for revision control. You should be able to just unpack the starter into the p4 directory of your cloned repo to get started. See the Getting Started section for instructions.
This project supports a number of our course objectives. See the Learning Outcomes section for a list.
You get to complete this project individually. If you're unsure what's permitted, you can have a look at the academic integrity guidelines in the course syllabus.
In the design section, you'll see some instructions for how your implementation is expected to work. Be sure you follow these rules. It's not enough to just turn in a working program; your program has to follow the design constraints we've asked you to follow. For this assignment, we're putting some constraints on the functions you'll need to define, the data structures you'll use and how you're going to organize your code into components. Still, you will have lots of opportunities to design parts of your solution and to create additional functions to simplify your implementation.
This section says what your program is supposed to be able to do, and what it should do when something goes wrong.
The agency program expects one or more filenames on the command line. Each of these files should contain a list of employees that the program can read at startup. If the program is run with invalid command-line arguments (e.g., no filenames given on the command line), it should print the following usage message to standard error and exit with a status of 1.
usage: agency <employee-file>*If the program can't open one of the given files for reading, it should print the following message to standard error and exit with a status of 1. Here, filename is the name of the file given on the command line. The program should report the first filename on the command line that it can't successfully open (i.e., if there are multiple filenames on the command line that can't be opened, it just needs to report this error for the first one that can't be opened).
Can't open file: filenameAt program start-up, the agency program reads in employees from one or more files and stores them in its database. On the command line, the program is given one or more filenames for files containing employee lists, stored in a particular format. Each line of an employee list file describes one employee. An employee description consists of four fields, with one or more spaces between the fields. The first field is a unique 4 digit employee ID number. Next there are three strings of up to 15 non-whitespace characters giving the employee's first name, last name, and skill, for example, Accounting, Administration, IT, Marketing, Sales, etc.
The program should process the employee list files in the same order they are given on the command line. Within each list, it should process employees in order from the first line to the last line of the file. An employee list file can contain any number of employee descriptions, one per line. If the format of the employee list is invalid (e.g., if a line is missing one of the expected fields, if an ID does not consist of exactly 4 digits, if a name/skill is too long), or if two or more employees have the same ID, then it should print the following message to standard error and exit with a status of 1. Here, filename is the name of the file containing the bad employee description.
Invalid employee file: filenameA few user commands are available for listing employees. The output format for these lists is the same for all these commands. It gives one employee per line. Each employee is listed as an ID, followed by a first name, last name, and skill each left-aligned in a 15-charfacter field. These fields are followed by the name of the company to which they are currently assigned or the word "Available" if they are not assigned to a company. The company name will be left-aligned in a 20-character field. There will be one space separating each of these fields, so an entire output line will take 73 characters. At the top, the employee list should give a header like the one shown below. The header line won't need any space as the end, after the word "Assignment". Thethe other lines may have some spaces at the end, to fill in the 20-columns field width used for the last field.
ID First Name Last Name Skill Assignment
1245 Martha Jones Accounting BusinessPros
3897 Sanket Patel Marketing Available
7659 Jennifer Chavez IT MaxRealty
After start-up, the agency program reads commands typed in by the user. Each command is given as single line of user input. For each command, the program will prompt the user with the following prompt. There's a space after the greater-than sign, but you probably can't see it in this web page.
cmd> After the user enters a command, the program will echo that command back to the user on the next output line (it will print a copy of the command the user just entered). This is mostly to help with debugging your programs. If we're capturing program output to a file, then things typed by the user don't go to the output file (user inputs show up on the terminal, but they're not part of the program's output). By echoing each command, our output files will include a copy of each command the user typed, making it easier to see what the program was asked to do. So, for example, if the user typed in a command like the following, the program would echo a copy of the command on the next line:
cmd> assign 3897 MaxReality assign 3897 MaxReality
The user can type any of 4 available commands: list, assign, unassign, and quit. These commands are described below. Each valid command starts with one of the keywords listed above. For some commands, the keyword may be followed by one or more parameters. There may be one or more whitespace characters at the start of the command, between the keyword and the parameter(s) or at the end of the command.
If the user enters an invalid command, the program should print the following message to standard output (not standard error), ignore the command and prompt the user for another command.
Invalid commandInvalid commands would be those that start with something other than the 4 keywords listed above, or if the command's parameters weren't correct. In general, including a parameter when the command doesn't expect one, or extra text after the last parameter would also be considered invalid. The command descriptions below describe what each command expects as valid parameters.
After the first prompt, the program should print a blank line before prompting the user for another command. This is shown in the sample execution at the start of this project description. It's just to provide a little separation between the output for consecutive commands.
The program should terminate when it is given the quit command or when it reaches the end-of-file on standard input. In the case of the quit command, the program should echo the command back to the user (like all the other commands). In the case of end-of-file, there's no command to echo, so the program should just terminate without echoing anything.
If the user enters the list command with no parameter after it, the program should print out all agency employees (all employees read at program start-up) in the format described in the "Employee List Output" section above. Employees should be sorted by their employee ID number.
cmd> list list ID First Name Last Name Skill Assignment 1245 Martha Jones Accounting BusinessPros 3897 Sanket Patel Marketing Available 7659 Jennifer Chavez IT MaxRealty
If the employee list is empty (if, say, the given employee list files were all empty) the program should just print out the header line for the employee list output.
A second form of the list command takes an optional parameter, skill, followed by a sequence of non-whitespace characters to match in a skill field. For example, if the user enters the following command, then the program should just list the employees whose skill is Accounting. Employees should be sorted by their employee ID number.
cmd> list skill Accounting list skill Accounting ID First Name Last Name Skill Assignment 1245 Martha Jones Accounting BusinessPros 4578 James Smith Accounting Available
Matching for skill names is case sensitive, so, for example, listing the skill "Accounting" would give different results than listing the skill "ACCOUNTING".
If there are no employees in the list, or if none of their skills match the given string, then the program should just print out the header line shown in the "Employee List Output" section, with no employees listed under it.
The second parameter can be any sequence of up to 15 non-witespace characters. If the word is too long or if it contains spaces (i.e., if it's more than one word), then the command is invalid.
A third form of the list command takes an optional parameter, assignment, followed by a sequence of non-whitespace characters that matches an employee's assignment, which may be the name of a company or the word, Available, if they are not assigned to a company. For example, if the user enters the following command, then the program should just list the employees who are assigned to the given company. Employees should be sorted by their skill and then by their employee ID number.
cmd> list assignment MaxRealty list assignment MaxRealty ID First Name Last Name Skill Assignment 1234 Thomas Baker Administration MaxRealty 4566 Jackie Walters Administration MaxRealty 7659 Jennifer Chavez IT MaxRealty
Matching an assignment name is case sensitive. For sorting the output, skills should be ordered lexicographically, in the same order given by strcmp. If there are no employees in the list, or if there are no employees whose assignment matches the second parameter, then the program should just print out the header line shown in the "Employee List Output" section, with no employees listed under it.
The second parameter can be any sequence of up to 20 non-whitespace characters. If the second parameter contains more than 20 characters, then the command is invalid.
The assign command lets the user assign an employee to a given company. The assign command expects an ID as the first parameter and a company name as the second parameter. For example, the following command assigns the employee with ID 7659 to the company, MaxReality.
cmd> assign 7659 MaxRealty assign 7659 MaxRealty
Other than echoing the user's command, the program doesn't need to print out any response to a valid assign command.
The assign command is invalid if its first parameter isn't an ID of an employee or if the employee is not Available (already assigned to a company, even if it's the given company). The second parameter can be any sequence of up to 20 non-whitespace characters. If the second parameter contains more than 20 characters, then the command is invalid.
The unassign command lets the user remove an employee from a company. As a parameter, it expects the ID of an employee that's currently assigned to a company. This command removes that employee from the company and sets the employee's assignment to Available.
cmd> unassign 7659 unassign 7659
Other than echoing the user's command, the program doesn't need to print out any response to a valid unassign command.
The unassign command must be given a parameter that matches the ID of an employee that's currently assigned to a company. Otherwise, it's considered an invalid command.
The quit command doesn't take any parameters. It should terminate the program. It's entered like the following:
cmd> quit
The program should also terminate successfully if it reaches the end-of-file on standard input while it's trying to read the next command.
Your implementation will be organized into three components. The input component will help with reading input from the employee list files and it will be used to read commands from the user. The database component will contain code for reading and managing the list of employees read in at startup. The agency component is the top-level component, containing main() and code to parse user commands.
The following figure shows the organization of these components. The agency component will use code from the other two, and the database component will use input to help with reading lines from the employee list files.
Figure: components and dependency structure
Since the input and database components provide functions that are used elsewhere in the program, they will each have a header file that prototypes these functions. The database header will also define types (e.g., structs) used elsewhere in the program. The top-level component won't need a header.
This project is a good chance to get some experience using structs, dynamic memory allocation and resizable arrays. Each employee will be represented by a struct, Employee, with a field for its ID, first name, last name, skill, and assignment. All fields will be stored as strings.
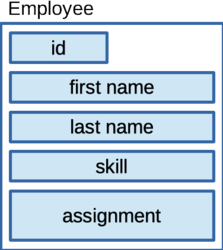
Figure: Employee representation
The Database (the list of all employees) will be represented by its own struct, containing fields to store a resizable array of pointers to Employee instances. Each Employee will be stored in a block of dynamically allocated memory. Inside the Database struct, you will use a resizable array of pointers to Employees to keep up with all the employees read in at start-up. The count and capacity fields are for maintaining the resizable array, for keeping up with how many Employees are in the Database and for detecting when you run out of capacity and need to grow the array. Your resizable array should start with an initial capacity of 5, and it should double in capacity whenever the array needs to be enlarged.
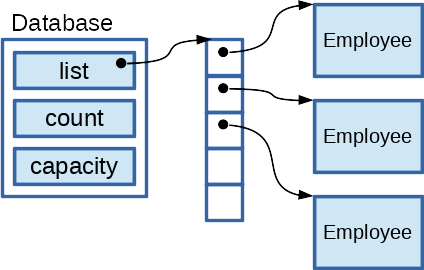
Figure: Database representation
As part of your implementation, you will define and use the following functions. You can define more if you want to. Just try to put them in a component that's suitable for whatever they do and remember to mark them as static where you can (i.e., if they're not used outside the component where they're defined).
Your input component only needs to have one function. It's kind of like the function we used in project 3, but this one is better. It can handle input lines of arbitrary length.
char *readLine( FILE *fp )Your database component should have the following five functions.
Database *makeDatabase()
This function dynamically allocates storage for the Database, initializes its fields (to store a resizable array) and returns a pointer to the new map. It's kind of like a constructor from Java.
void freeDatabase( Database *database )
This function frees the memory used to store the given database, including freeing space for all the Employees, freeing the resizable array of pointers and freeing space for the Database struct itself.
void readEmployees( char const *filename, Database *database )
This function reads all the employees from an employee list file with the given name. It makes an instance of the Employee struct for each one and stores a pointer to that Employee in the resizable array in database.
void listEmployees( Database *database, int (*compare)( void const *va, void const *vb ), bool (*test)( Employee const *emp, char const *str ), char const *str )
This function sorts the employees in the given database and then prints them. It uses the first function pointer parameter to decide the order for sorting the employees. It uses the second function pointer parameter together with the string, str, which is passed to the function, to decide which employees to print. This function will be used to list employees for the list commands. The function pointers are described in the "Sorting Employees" and "Listing Employees" sections below.
Your agency component will contain main() and any other functions you need to parse command-line arguments and user commands.
With help from your input component, it will be easy to read user input one line at a time. After you get a line of input from the user, you will need to look inside this string to figure out what command the user typed. The sscanf() function will make it easy to do this. It works much like scanf() or fscanf(), but it parses input from a string instead of from a file. We'll cover this function in lecture 19, but you may want to look at the material for lecture 19 early (it should already be posted) so you can get started on the project earlier.
Remember, unlike reading from a file, sscanf() doesn't automatically resume parsing from where it left off on the last call. For example, you couldn't call something like sscanf( str, "%d", &x ); to read an int then call sscanf( str, "%d", &y ); again to read the next int. If you gave sscanf() the same string in two successive calls, it would just start parsing at the start of the string each time. If you want to parse multiple values out of the same string, you can do it all at once, like sscanf( str, "%d%d", &x, &y );, or you could advance the pointer on successive calls to sscanf(), as in sscanf( str + offset, "%d", &y );. If you need to do this, the %n conversion specifier we covered in lecture 10 can be helpful.
Any functions that are needed by a different component should be prototyped (and commented) in the header. Functions that don't need to be used by a different component should not be prototyped in the header, and should be marked static (given internal linkage), so they won't be visible to any other part of the program. This is like making the function an implementation detail of its component, something we could change if we wanted without affecting other parts of the program.
You'll use the standard library qsort() function to sort the array of employee pointers inside the database struct, ordering them either by id (for the list and list skill commands) or by skill followed by id (for the list assignment command). Using qsort() will make the sorting easier (and probably more efficient), but you have to help out qsort() by providing a pointer to a comparison function. We have some examples of this in the material from lecture 13, in the slides and in the sort.c example program.
To use qsort() you'll need to think about a few things. As usual, you'll need to write your own comparison function(s). These functions will have to be declared to take two (const) void pointers as parameters. However, the functions will know the specific type of data that these pointers really point to. You'll use qsort() to sort your array of pointers to Employees, so the void pointers qsort() passes to your compare function will really be pointers to two of these array elements. The array elements are all pointers to Employees, so the parameters to a comparison function will really be pointers to pointers to Employees. Inside the function, you can convert the two void pointers to the right type for what they're really pointing to. Then, you can use them to access fields in Employee structs and decide how they compare. As we discussed in class, your comparison function should return -1 if the employee given by the fist parameter should be ordered before the second one, it should return 1 if the employee given by the first parameter should come after the second one, and it should return 0 if they're considered equal.
The listEmployees() function expects a compare function pointer as a parameter. It will pass in this function as the last parameter to qsort(). This way, code elsewhere in the program can use listEmployees() function to print out employees in any order it wants, by providing listEmployees() with a pointer to an appropriate comparison function. You can define the comparison functions you need in your top-level agency component. You can make them static. Other components won't be able to call these functions by name, but listEmployees() will still be able to call a static comparison function if you pass in a pointer to it.
The listEmployees() function can be used to print all the employees in the database, or just selected ones. This will let us use it to implement the list command, with or without a string to match.
How does listEmployees() know which employees to report? Internally, it will call the provided test function for each Employee in the database with the provided string. If the test function returns true, listEmployees()should print that Employee; otherwise, it shouldn't. This lets client code use a single interface to print any subset of the Employees. The client code just needs to provide a pointer to a function listEmployees() can use to decide what to print and what not to print.
To print all Employees, you can pass in a pointer to a test function that always returns true and simply provide NULL as the string parameter. To print Employees that match a particular skill, you can pass in a pointer to a function that checks if the provided string matches the Employee's skill. Likewise, to print Employees that match a particular assignment, you can pass in a pointer to a function that checks if the provided string matches the Employee's assignment.
Normally, printf will right-align output values in a given field width. You can use a negative value for the field width to get it to left align instead.
You get to implement your own Makefile for this project (called Makefile with a capital 'M', no filename extension). Its default target should build your program, compiling each source file to an object file and then linking the objects together into an executable.
As usual, your Makefile should correctly describe the project's dependencies, so targets can be rebuilt selectively, based on what source files have changed. It should also have a clean rule, to let the user easily delete any temporary files or target files that can be rebuilt the next time make is run (e.g., the object files, the executable and any temporary output files).
In addition to the "-Wall" and "-std=c99" options that we normally include when we're compiling, be sure to include the "-g" flag. This will be useful when you try to use gdb or valgrind to help debug the program.
The starter includes a test script, along with test input files and expected outputs. When we grade your program, we'll test it with this script, along with a few other test inputs we're not giving you. To run the automated test script, you should be able to enter the following:
$ chmod +x test.sh # probably just need to do this once
$ ./test.shThis will automatically build your program (using your Makefile) and see how it does against all the tests.
As you develop your program, you'll want to try it out with user input and see what it's doing on individual test cases. Until your Makefile is working, you should be able to execute the compiler directly with the following command (although this isn't as efficient as how your Makefile builds).
$ gcc -g -Wall -std=c99 agency.c database.c input.c -o agencyTo try out your program on one of the provided test cases, you can run it as follows. Here, we're saving the program's standard output and standard error to two different files. All of the tests have an expected output file for stdout, and some of them (the ones that exit unsuccessfully) also have an expected error output to stderr.
Here, we're running test 06 by hand. After running the program, we check its exit status to make sure it ran successfully (it should for this test). Then we check the output file to make sure we got what was expected. This particular test shouldn't print any output to the standard error stream, but error tests will.
./agency list-b.txt list-c.txt < input-06.txt > output.txt 2> stderr.txt
$ echo $?
0
$ diff output.txt expected-06.txt
$ cat stderr.txtOn any test that runs successfully, your program is expected to free all of the dynamically allocated memory it allocates and close any files it opens. Although it's not part of an automated test, we encourage you to try out your executable with valgrind. We certainly will when we're grading your work. Any leaked memory, use of uninitialized memory, access to memory outside the range of an allocated block or leaked files will cost you some points. Valgrind can help you find these errors before we do.
Your program is not expected to free memory or close all its files on error tests, those tests where your program is supposed to exit unsuccessfully. On these test cases, your program may need to exit from inside some function, where you don't have access to all the memory you've allocated or all the files you've opened. In these cases, your program can just exit right away, without having to free all resources.
The compile instructions above include the -g flag when building your program. This will help valgrind give more useful reports of where it sees errors. To get valgrind to check for memory errors, including memory leaks, you can run your program like the following. This example runs the program on input 09, a test input that uses several of the supported commands. You can use similar commands to try your program on any input using valgrind.
$ valgrind --leak-check=full --show-leak-kinds=all --track-fds=yes ./agency list-b.txt list-c.txt < input-09.txt
... lots of output ...If you want to run valgrind, you have to run it on each test case individually. You can't run the test script inside valgrind (well, you can, but then you will be getting valgrind output for the shell, rather than for the program you wrote). I've seen students try to run something like "valgrind test.sh". Just be aware that this won't work. You have to run valgrind like the example above.
The tests for your program use the following employee list files. These contain various-sized lists of employees, along with some invalid lists for testing error handling.
list-a.txt : This list just contains one employee.
list-b.txt : This list contains 5 employees, but they're already in the order they should be for the list command.
list-c.txt : This list contains 15 employees in a random order. Reading this file will require growing your resizable array, and the list command will require getting them sorted into the right order.
list-d.txt : This list contains 999 employees in a random order. The employee skills are based on the list of common jobs found at https://foxhugh.com/list-of-lists/list-of-common-jobs/
list-e.txt : This list contains an invalid entry, with a last name that's too long.
list-f.txt : This list contains an invalid entry. One line is missing a field.
list-g.txt : This list contains an invalid entry. One id does not contain exactly four digits.
list-h.txt : This list contains two employees with the same id.
We've prepared 21 tests for your program. Using the employee lists above, they exercise the various commands your program is supposed to support, working from the easier ones to the more difficult tests and error cases. In developing your program, you may want to follow the order of these tests, adding the code to support the first test, then working toward the later (more complex) tests as you get the earlier ones working.
This test reads the list-a.txt file, but it runs the quit command immediately.
This test reads the list-b.txt file. It runs the list command then input ends at the end-of-file on the input, rather than a quit command (which should be OK).
This test reads the list-b.txt and list-a.txt files. This requires the program to read two employee files and it should require growing of the resizable array in Database. It uses the list and quit commands.
This test reads the list-b.txt and list-c.txt files and uses the list command. This requires growing the resizable array twice and it requires being able to sort employees by id.
This test reads the list-b.txt list-c.txt files. It then lists employees with a given skill.
This test reads the list-b.txt list-c.txt files. It then lists employees with the assignment, Available, which requires sorting the employees by skill and then by id before listing them.
This test reads the list-b.txt and list-c.txt files. It then assigns several employees to companies and then lists all employees.
This test reads the list-b.txt list-c.txt files. It then assigns several employees to companies, unassigns some of them and then lists all employees.
This is the example shown at the start of the assignment. It uses several different commands.
This test reads the list-d.txt file and then lists all employees with a given skill.
This test reads the list-d.txt file and assigns some employees to various companies, then lists the employees assigned to each of the companies.
This test reads the list-d.txt file and assigns some employees to various companies, unassigns some of them, then lists the employees assigned to each of the companies.
This test reads the list-a, list-b.txt, and list-c.txt files and performs a variety of commands.
This test contains a few bad commands. They shouldn't terminate the program, but they should get an Invalid Command message.
This test includes some list commands that don't match anything and list commands with bad parameters.
This is an error test, with no files given on the command line.
This is an error test. A filename given on the command line doesn't exist.
This is an error test. The employee list contains a last name that's too long.
This is an error test. One line of the employee list is missing a field.
This is an error test. One line of the employee list has an id that does not contain exactly 4 digits.
This is an error test. Two employees have the same id number.
The grade for your program will depend mostly on how well it functions. You also get to provide your own Makefile, and we'll expect your program to compile cleanly, to follow the style guide and to adhere to the expected design.
To get started on this project, you'll need to clone your NCSU github repo and unpack the given starter into the p4 directory of your repo. You'll submit by committing files to your repo and pushing the changes back up to the NCSU github.
You should have already cloned your assigned NCSU github repo when you were working on project 2. If you haven't already done this, go back to the assignment for project 2 and follow the instructions for for cloning your repo.
You will need to copy and unpack the project 4 starter. We're providing this file as a compressed tar archive, starter4.tgz. You can get a copy of the starter by using the link in this document, or you can use the following curl command to download it from your shell prompt.
$ curl -O https://www.csc2.ncsu.edu/courses/csc230/proj/p4/starter4.tgzTemporarily, put your copy of the starter in the p4 directory of your cloned repo. Then, you should be able to unpack it with the following command:
$ tar xzvpf starter4.tgzOnce you start working on the project, be sure you don't accidentally commit the starter to your repo. After you've successfully unpacked it, you may want to delete the starter from your p4 directory, or move it out of your repo.
$ rm starter4.tgzIf you've set up your repository properly, pushing your changes to your assigned CSC230 repository should be all that's required for submission. When you're done, we're expecting your repo to contain the following files. You can use the web interface on github.ncsu.edu to confirm that the right versions of all your files made it.
agency.c : Source file for the top-level component, written by you.database.h : Header for the database component, written by you.database.c : Implementation file for the database component, written by you.input.h : Header for the input component, written by you.input.c : Implementation file for the input component, written by you.Makefile : the project's Makefile, written by you.list-*.txt : employee lists for the tests, provided with the starter.input-*.txt : test inputs given to the program on standard input, provided with the starter.expected-*.txt : expected output from the program, provided with the starter.error-*.txt : expected standard error output for the error test cases, provided with the starter.test.sh : test script, provided with the starter..gitignore : a file provided with the starter, to tell git not to track temporary files specific to this project.To submit your project, you'll need to commit your changes to your cloned repo, then push them to the NCSU github. Project 2 has more detailed instructions for doing this, but I've also summarized them here.
Whenever you create a new file that needs to go into your repo, you need to stage it for the next commit using the add command:
$ git add some-new-fileThen, before you commit, it's a good idea to check to make sure your index has the right files staged:
$ git statusOnce you've added any new files, you can use a command like the following to commit them, along with any changes to files that were already being tracked:
$ git commit -am "<meaningful message for future self>"Of course, you haven't really submitted anything until you push your changes up to the NCSU github:
$ git pushChecking Jenkins feedback is similar to previous projects. Visit our Jenkins system at http://go.ncsu.edu/jenkins-csc230 and you'll see a new build job for project 4. This job polls your repo periodically for changes and rebuilds and tests your project automatically whenever it sees a change.
The syllabus lists a number of learning outcomes for this course. This assignment is intended to support several of theses:
Write small to medium C programs having several separately-compiled modules.
Explain what happens during preprocessing, lexical analysis, parsing, code generation, code optimization, linking, and execution. Explain the function and organization of relevant, intermediate formats, including pre-processor expanded source code, object files and executables. Compare and contrast the build and execute behavior between C and Java.
Identify errors that can occur during various compilation phases, identify relevant error messages and warnings, and appropriately correct these errors.
Correctly identify error messages and warnings from the preprocessor, compiler, and linker, and avoid them.
Find and eliminate runtime errors using a combination of logic, language understanding, trace printout, and gdb or a similar command-line debugger.
Interpret and explain data types, conversions between data types, and the possibility of overflow and underflow.
Explain, inspect, and implement programs using structures such as enumerated types, unions, and constants and arithmetic, logical, relational, assignment, and bitwise operators.
Trace and reason about variables and their scope in a single function, across multiple functions, and across multiple modules.
Allocate and deallocate memory in C programs while avoiding memory leaks and dangling pointers. In particular, they will be able to implement dynamic arrays and singly-linked lists using allocated memory.
Use the C preprocessor to control tracing of programs, compilation for different systems, and write simple macros.
Write, debug, and modify programs using library utilities, including, but not limited to assert, the math library, the string library, random number generation, variable number of parameters, standard I/O, and file I/O.
Use simple command-line tools to design, document, debug, and maintain their programs.
Use an automatic packaging tool, such as make or ant, to distribute and maintain software that has multiple compilation units.
Use a version control tool, such as subversion (svn) or Git, to track changes and do parallel development of software.
Distinguish key elements of the syntax (what's legal), semantics (what does it do), and pragmatics (how is it used) of a programming language.
Describe and demonstrate how to avoid the implications of common programming errors that lead to security vulnerabilities, such as buffer overflows and injection attacks.